java 集合框架
java 集合框架
一、集合概念
对象的容器,定义了对多个对象进行操作的常用方法,可以实现数组的功能
和数组的区别
(1)数组长度固定,集合长度不固定
(2)数组可以存储基本类型和引用类型,集合只能存储引用类型
(3)位置 java.util.*
二、Collection
2.1 Collection体系
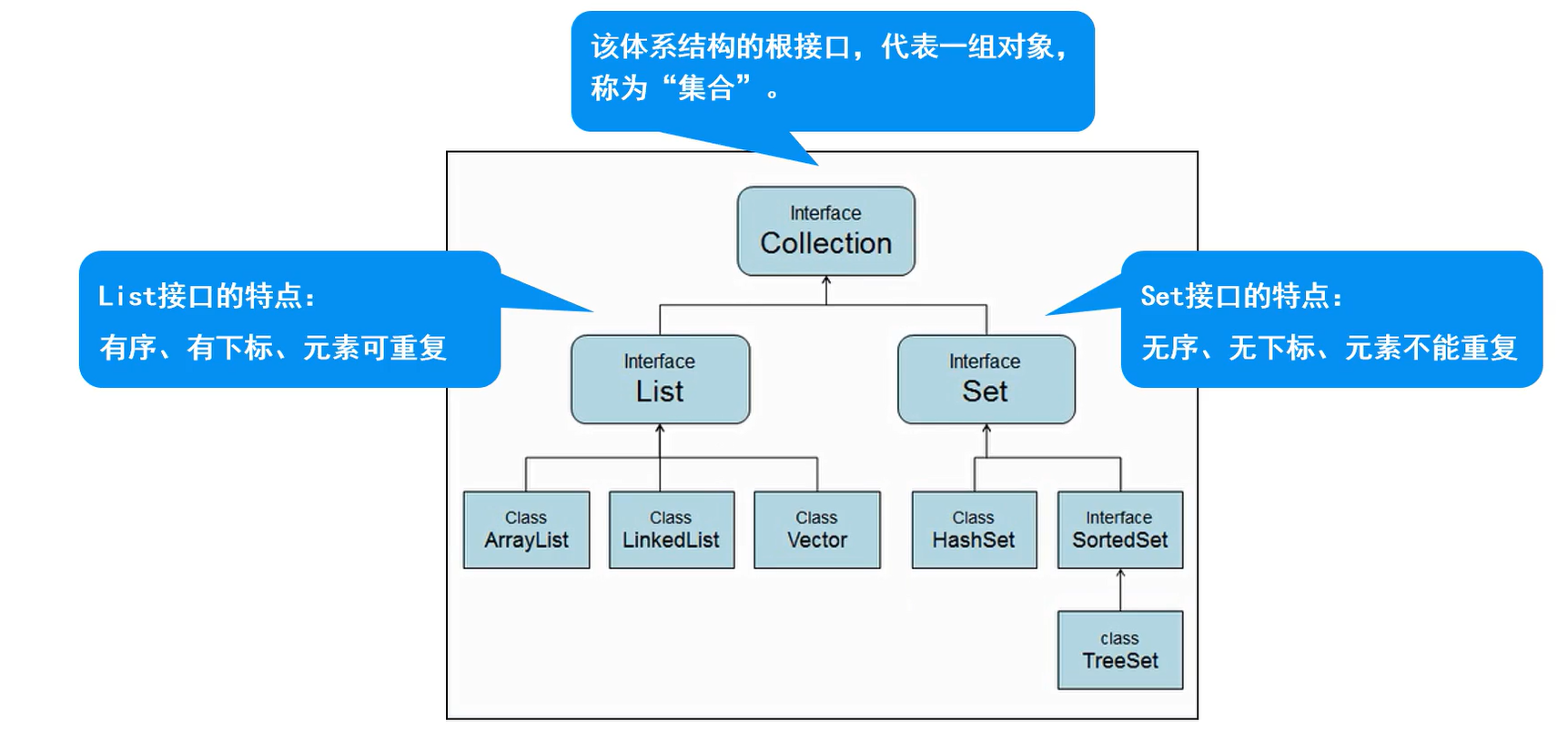
2.2 Collection接口
特点:代表一组任意类型的对象,无序、无下标、不能重复
2.3 Collection使用
package oop3;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
/**
* Collection接口的使用
* (1)添加
* (2)删除
* (3)遍历元素
* (4)判断
*/
public class TestA {
public static void main(String[] args) {
//创建集合
Collection collection = new ArrayList();
//添加
collection.add("苹果");
collection.add("香蕉");
collection.add("西瓜");
System.out.println("元素个数"+collection.size());
//删除
collection.remove("西瓜");
System.out.println("元素个数"+collection.size());
//清空 collection.clear();
//遍历
//增强for的遍历 ,一般的for循环不能使用,因为ArrayList没有下标,遍历不了
for (Object o :collection){
System.out.println(o);
}
// 使用迭代器遍历
//hasNext(); 有没有下一个元素
// next(); 获取下一个元素
// remove(); 删除当前元素
Iterator it = collection.iterator();
while (it.hasNext()){ //使用迭代器不能使用 collection.remove(),
// 但是可以使用it.remove();
String s = (String) it.next();
System.out.println(s);
it.remove();
}
System.out.println("元素个数"+collection.size());
//判断是否有xx元素
System.out.println(collection.contains("苹果"));
}
}
使用2
package oop3;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
/**
* collection的使用:保存学生信息
*/
public class TestB {
public static void main(String[] args) {
//新建一个collection对象
Collection collection = new ArrayList();
//添加
Student s1 = new Student("张三", 17);
Student s2 = new Student("李四", 19);
Student s3 = new Student("王五", 18);
collection.add(s1);
collection.add(s2);
collection.add(s3);
System.out.println("元素个数"+collection.size());
System.out.println(collection.toString());
//删除
collection.remove(s1);
System.out.println("删除之后的个数"+collection.size());
//清空 collection.clear();
//遍历
//增强for遍历
for (Object o : collection){
Student s = (Student) o;
System.out.println(s.toString());
}
//迭代器遍历
Iterator iterator = collection.iterator();
while (iterator.hasNext()){
Student student = (Student) iterator.next();
System.out.println(student.toString());
}
//判断
System.out.println(collection.contains(s2));
System.out.println(collection.isEmpty());
}
}
package oop3;
public class Student {
private String Name;
private int age;
public Student(){
}
public Student(String name, int age) {
Name = name;
this.age = age;
}
public String getName() {
return Name;
}
public void setName(String name) {
Name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"Name='" + Name + '\'' +
", age=" + age +
'}';
}
}
三、List接口与实现类
3.1 List子接口
特点:有序、有下标、元素可以重复
3.2 List接口使用
package oop3;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.ListIterator;
/**
* List子接口的使用
*
*
*/
public class TestC {
public static void main(String[] args) {
List list = new ArrayList<>();
//添加
list.add("苹果");
list.add("小米");
list.add("华为");
System.out.println("元素个数"+list.size());
//删除
list.remove("苹果");
System.out.println("删除之后元素个数"+list.size());
System.out.println(list.toString());
//遍历
//for遍历
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
//增强for遍历
for (Object o : list){
System.out.println(o);
}
//迭代器Iterator遍历
Iterator iterator = list.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
}
//列表迭代器遍历,和Iterator和ListIterator的区别:ListIterator可以任意方向遍历,添加删除修改元素
ListIterator lis = list.listIterator();
System.out.println("===============列表迭代器:从前往后==================");
while (lis.hasNext()){
System.out.println(lis.nextIndex() + ":" + lis.next());
}
System.out.println("===============列表迭代器:从后往前==================");
while (lis.hasPrevious()){
System.out.println(lis.previousIndex() + ":" + lis.previous());
}
//判断
System.out.println(list.contains("苹果"));
System.out.println(list.isEmpty());
//获取位置
System.out.println(list.indexOf("华为"));
}
}
java的使用2
package oop3;
import java.util.ArrayList;
import java.util.List;
public class TestD {
public static void main(String[] args) {
List list = new ArrayList();
//添加数字数据,会自动装箱
list.add(20);
list.add(30);
list.add(40);
list.add(50);
list.add(60);
System.out.println("元素个数"+list.size());
System.out.println(list.toString());
//删除操作
// list.remove(20); //remove 是根据脚标来是删除的
list.remove((Object) 20); //删除需要转成对象类型
System.out.println(list.toString());
//补充方法sublist :返回子集合。含头不含尾
List subList = list.subList(0, 3); //返回脚标 0 1 2 的对象值
System.out.println(subList.toString());
}
}
3.3 List实现类
3.3.1ArrayList【重点】
特点数组结构实现,查询快、增删慢
运行效率快,线程不安全
package oop3;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.ListIterator;
/**
* ArrayList的使用
* 数组,查找遍历快,增删慢
*
*/
public class TestE {
public static void main(String[] args) {
ArrayList arrayList = new ArrayList<>();
Student s1 = new Student("刘德华", 20);
Student s2 = new Student("郭富城", 22);
Student s3 = new Student("梁朝伟", 18);
//增加
arrayList.add(s1);
arrayList.add(s2);
arrayList.add(s3);
System.out.println("元素个数"+arrayList.size());
System.out.println(arrayList.toString());
//删除
//arrayList.remove(s1);
arrayList.remove(new Student("刘德华",20));
System.out.println("元素个数"+arrayList.size());
//遍历
//迭代器1 遍历
Iterator iterator = arrayList.iterator();
while (iterator.hasNext()){
Student s = (Student) iterator.next();
System.out.println(s.toString());
}
//列表迭代器遍历
ListIterator lit = arrayList.listIterator();
while (lit.hasNext()){
Student student = (Student)lit.next();
System.out.println(student.toString());
}
while (lit.hasPrevious()){
Student student = (Student)lit.previous();
System.out.println(student.toString());
}
//判断
System.out.println(arrayList.contains(s1));
//查找位置
System.out.println(arrayList.indexOf(s2));
}
}
3.3.2源码分析
ArrayList
默认容量 DEFAULT_CAPACITY = 10
注意:如果集合没有添加任何元素,则容量0
每次扩容大小是原来的1.5倍
存放元素的数组 elementData
实际的元素个数:size
添加元素 add()
3.4 Vector(少用)
数组结构实现,查询快,增删慢
运行效率慢,线程安全
package oop3;
import java.util.Enumeration;
import java.util.Vector;
/**
* Vector集合使用
* 存储结构:数组
*/
public class TestF {
public static void main(String[] args) {
//创建
Vector vector = new Vector<>();
vector.add("芒果");
vector.add("草莓");
vector.add("西瓜");
System.out.println("元素个数"+vector.size());
/**
* 删除
*/
// vector.remove(0);
// vector.remove("西瓜");
// vector.clear();
//遍历
//使用枚举器
Enumeration en = vector.elements();
while (en.hasMoreElements()){
String o = (String) en.nextElement();
System.out.println(o);
}
//判断
System.out.println(vector.contains("西瓜"));
System.out.println(vector.isEmpty());
//vector的其他方法
vector.firstElement();
vector.lastElement();
vector.elementAt(2);
}
}
3.5 LinkedList (链表)
存储结构是双向链表
链表结构实现,增删快,查询慢
package oop3;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.ListIterator;
/**
* LinkedList 的使用
* 存储结构是 双向链表
*/
public class TestG {
public static void main(String[] args) {
Student s1 = new Student("刘德华", 20);
Student s2 = new Student("郭富城", 22);
Student s3 = new Student("梁朝伟", 18);
LinkedList linkedList = new LinkedList();
linkedList.add(s1);
linkedList.add(s2);
linkedList.add(s3);
System.out.println("元素个数"+ linkedList.size());
System.out.println(linkedList.toString());
//删除
linkedList.remove(s1);
System.out.println("删除之后"+linkedList.size());
//遍历
//for遍历
for (int i = 0; i < linkedList.size(); i++) {
System.out.println(linkedList.get(i));
}
//增强for
for (Object o:linkedList){
Student student = (Student) o;
System.out.println(o.toString());
}
//迭代器遍历
Iterator iterator = linkedList.iterator();
while (iterator.hasNext()){
Student s = (Student) iterator.next();
System.out.println(s.toString());
}
ListIterator lit = linkedList.listIterator();
while (lit.hasPrevious()){
Student student = (Student)lit.previous();
System.out.println(student.toString());
}
//判断
System.out.println(linkedList.contains(s1));
System.out.println(linkedList.isEmpty());
//获取
System.out.println(linkedList.indexOf(s2));
}
}
3.7 源码分析
LinkedList首先有三个属性:
- 链表大小:
transient int size = 0; - (指向)第一个结点/头结点:
transient Node<E> first; - (指向)最后一个结点/尾结点:
transient Node<E> last;
ArrayList和LinkedList的区别
- ArrayList:必须开辟连续空间,查询快,增删慢。
- LinkedList:无需开辟连续空间,查询慢,增删快。
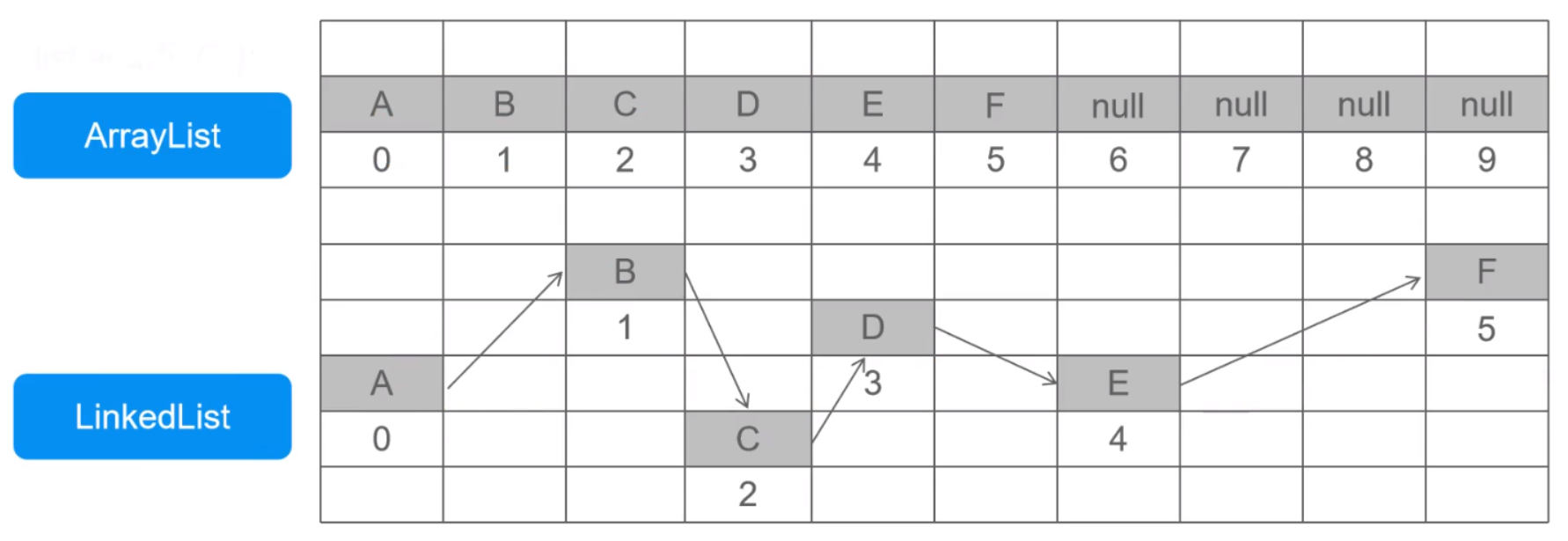
四、泛型和工具栏
4.1泛型方法
其本质是参数化类型,把类型作为参数传递。
- 语法:
- <T,…> T称为类型占位符,表示一种引用类型。
- 好处:
- 提高代码的重用性。
- 防止类型转换异常,提高代码的安全性。
4.2泛型类
package oop4;
/**
* 泛型类
* 语法 类名<T,E,K>
* T是类型占位符,表示引用类型,如果编写多个使用逗号隔开
*/
public class myGeneric<T> {
//创建泛型T
//创建变量
T t;
//泛型作为方法的参数
public void show(T t){
System.out.println(t);
}
//使用泛型作为方法的返回值
public T getT(){
return t;
}
}
(注意使用泛型类创建对象)
package oop4;
public class testGeneric {
public static void main(String[] args) {
//使用泛型类创建对象
//注意:
/**
* 泛型只能使用引用类型
* 不同泛型类对象之间不能相互赋值
*/
myGeneric<String> myGeneric1 = new myGeneric<String>();
myGeneric1.t = "hello";
myGeneric1.show("大家好");
String str = myGeneric1.getT();
myGeneric<Integer> myGeneric2 = new myGeneric<>();
myGeneric2.t = 100;
myGeneric2.show(200);
Integer intger = myGeneric2.getT();
}
}
4.3泛型接口
package oop4;
/**
* 泛型接口
* 语法: 接口名<T>
*/
public interface MyInterface<T> {
String name = "张三";
T server(T t);
}
package oop4;
public class MyInterfaceImpl implements MyInterface<String> {
@Override
public String server(String t) {
System.out.println(t);
return null;
}
}
package oop4;
public class MyInterfaceImpl2<T> implements MyInterface<T>{
@Override
public T server(T t) {
System.out.println(t);
return null;
}
}
package oop4;
public class testGeneric {
public static void main(String[] args) {
//使用泛型类创建对象
//注意:
/**
* 泛型只能使用引用类型
* 不同泛型类对象之间不能相互赋值
*/
//接口
MyInterfaceImpl impl = new MyInterfaceImpl();
impl.server("xxxxxx");
//接口的第二种使用方法
MyInterfaceImpl2<Integer> impl2 = new MyInterfaceImpl2<>();
impl2.server(100);
}
}
4.4 泛型方法
package oop4;
/**
* 泛型方法
* 语法 <T> 返回值类型
*/
public class myGenericMeth {
//泛型方法
public <T> void show(T t){
System.out.println("泛型方法" + t);
}
//泛型方法的多种方式
// public static <T> T show2(T t){
// T t2;
// System.out.println("泛型方法" + t);
// return t;
// }
}
package oop4;
public class testGeneric {
public static void main(String[] args) {
//使用泛型类创建对象
//注意:
/**
* 泛型只能使用引用类型
* 不同泛型类对象之间不能相互赋值
*/
//调用泛型方法,可以有多种类型
myGenericMeth myGen = new myGenericMeth();
myGen.show("中国加油");
myGen.show(200);
myGen.show(3.14);
}
}
提高代码的重用性
4.5泛型集合
参数化类型、类型安全的集合,强制集合元素的类型必须一致。
特点
- 编译时即可检查,而非运行时抛出异常。
- 访问时,不必类型转换(拆箱)。
- 不同泛型指尖引用不能相互赋值,泛型不存在多态。
package oop3;
import java.util.ArrayList;
import java.util.Iterator;
public class TsetH {
public static void main(String[] args) {
Student s1 = new Student("刘德华", 20);
Student s2 = new Student("郭富城", 22);
Student s3 = new Student("梁朝伟", 18);
ArrayList a = new ArrayList();
a.add(s1);
a.add(s2);
a.add(s3);
Iterator<Student> iterator = a.iterator(); //iterator转成了Student,就又不需要像之前的一样,到while里边再多次强转。其底层的代码也是用来泛型的方法
while (iterator.hasNext()){
Student student = iterator.next();
System.out.println(student.toString());
}
}
}
五、Set接口与实现类
Set接口的特点:无序、无下标,元素不可重复
方法:全部继承自Collection中的方法。
package oop5;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
/**
* 测试set接口的使用
* 特点:无序没有下标,不能重复
*/
public class Demo1 {
public static void main(String[] args) {
Set<String> set = new HashSet<>();
set.add("苹果");
set.add("华为");
set.add("小米");
System.out.println("数据个数"+set.size());
System.out.println(set.toString());
//删除
set.remove("小米");
System.out.println(set.toString());
//遍历(重点)
//使用增强for遍历
for (Object o : set){
System.out.println(o);
}
//使用迭代器遍历
Iterator<String> iterator = set.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
}
//判断
System.out.println(set.contains("华为"));
System.out.println(set.isEmpty());
}
}
5.1HashSet(重点)
5.1.1 使用一
package oop5;
import java.util.HashSet;
import java.util.Iterator;
/**
* HashSet集合的使用
* 存储结构:哈希表(数组+链表+红黑树)
*/
public class Demo2 {
public static void main(String[] args) {
//新建集合
HashSet<String> hashSet = new HashSet<>();
hashSet.add("甘雨");
hashSet.add("七七");
hashSet.add("可莉");
hashSet.add("叶兰");
System.out.println(hashSet.size()); //元素个数
System.out.println(hashSet.toString());
//删除
hashSet.remove("叶兰");
System.out.println(hashSet.size());
//遍历
//增强for
for (Object o : hashSet){
System.out.println(o);
}
//迭代器遍历
Iterator<String> iterator = hashSet.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
}
//判断
System.out.println(hashSet.contains("可莉"));
System.out.println(hashSet.isEmpty());
}
}
5.1.2使用二
package oop5;
import java.util.Objects;
/**
* 人类
*/
public class Person {
private String name;
private int age;
public Person(){
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
// @Override
// public int hashCode() {
// final int prime = 31;
// int result = 1;
// result = prime * result +age;
// result = prime * result +((name == null) ? 0 : name.hashCode());
// return result;
//
// }
//
// /**
// * hashCode方法里为什么要使用31这个数字大概有两个原因:
// * 31是一个质数,这样的数字在计算时可以尽量减少散列冲突。
// * 可以提高执行效率,因为31*i=(i<<5)-i,31乘以一个数可以转换成移位操作,这样能快一点;但是也有网上一些人对这两点提出质疑。
// *
// *
// * link:https://lazydog036.gitee.io/2020/10/29/JAVA%E9%9B%86%E5%90%88%E6%A1%86%E6%9E%B6/#Set%E9%9B%86%E5%90%88%E6%A6%82%E8%BF%B0
// */
//
//
// @Override
// public boolean equals(Object obj) { //重写 equals
// if (this==obj){
// return true;
// }
// if (obj==null){
// return false;
// }if (obj instanceof Person){
// Person person = (Person) obj;
// if (this.name.equals(person.getName())&&this.age==person.getAge()){
// return true;
// }
// }
// return false;
// }
//
//快速生成hashcode和equals
//ALT + Insert
//如下;新版的IDEA生成的内容可能会跟教程的不一样
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return age == person.age && name.equals(person.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
package oop5;
import java.util.HashSet;
import java.util.Iterator;
/**
* hashset的使用2
* 存储结构: 哈希表(数组+链表+红黑树)
* 存储过程:
* (1)根据hashcode,计算保存的位置,如果此位置为空则直接为空。如果不为空执行第二步
* (2)再执行equals方法,如果equals方法为true,则认为重复,否则,形成链表
*/
public class Demo3 {
public static void main(String[] args) {
HashSet<Person> hashSet = new HashSet<>();
Person person1 = new Person("甘雨",3000);
Person person2 = new Person("钟离",6000);
Person person3 = new Person("八重神子",500);
hashSet.add(person1);
hashSet.add(person2);
hashSet.add(person3);
//重复不能添加进去
hashSet.add(new Person("甘雨",3000));
System.out.println(hashSet.toString());
System.out.println(hashSet.size());
//删除
hashSet.remove(person1);
hashSet.remove(new Person("八重神子",500)); //可以删掉。但是没有重写hashcode和equals的时候就删不了
//遍历
for ( Person p : hashSet){
System.out.println(p.toString());
}
Iterator<Person> iterator = hashSet.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
}
//判断
System.out.println(hashSet.contains(person1));
System.out.println(hashSet.isEmpty());
System.out.println(hashSet.contains(new Person("钟离",6000)));
}
}
5.2 TreeSet
5.2.1TreeSet概述
- 基于排序顺序实现不重复。
- 实现了SortedSet接口,对集合元素自动排序。
- 元素对象的类型必须实现Comparable接口,指定排序规则。
- 通过CompareTo方法确定是否为重复元素。
package oop5;
import java.util.Iterator;
import java.util.TreeSet;
/**
* TreeSet的使用
* 存储结构:红黑树
*/
public class Demo4 {
public static void main(String[] args) {
//创建一个集合
TreeSet<String> treeSet = new TreeSet();
treeSet.add("xyz");
treeSet.add("abc");
treeSet.add("hello");
System.out.println(treeSet.size());
System.out.println(treeSet.toString());
treeSet.remove("xyz");
System.out.println(treeSet.size());
//遍历
for (Object o : treeSet){
System.out.println(o);
}
Iterator<String> iterator = treeSet.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
}
//判断
System.out.println(treeSet.contains("abc"));
}
}
5.2.2 TreeSet使用
package oop5;
import java.util.Iterator;
import java.util.TreeSet;
/**
* 使用TreeSet保存数据
* 存储结构:红黑树
* 要求:元素必须实现Comparable接口,compareTo()方法返回值为0,认为是重复元素
*/
public class Demo5 {
public static void main(String[] args) {
TreeSet<Person> people = new TreeSet<>();
Person person1 = new Person("甘雨",3000);
Person person2 = new Person("钟离",6000);
Person person3 = new Person("八重神子",500);
//添加
people.add(person1);
people.add(person2);
people.add(person3);
System.out.printf("元素个数%d%n", people.size());
System.out.println(people.toString());
//删除
people.remove(person1);
System.out.println(people.size());
//遍历
for (Person p : people){
System.out.println(p);
}
Iterator<Person> iterator = people.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
}
//判断
System.out.println(people.contains(person1));
}
}
package oop5;
import java.util.Objects;
/**
* 人类
*/
public class Person implements Comparable<Person>{ //implements Comparable<Person>
private String name;
private int age;
public Person(){
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
// @Override
// public int hashCode() {
// final int prime = 31;
// int result = 1;
// result = prime * result +age;
// result = prime * result +((name == null) ? 0 : name.hashCode());
// return result;
//
// }
//
// /**
// * hashCode方法里为什么要使用31这个数字大概有两个原因:
// * 31是一个质数,这样的数字在计算时可以尽量减少散列冲突。
// * 可以提高执行效率,因为31*i=(i<<5)-i,31乘以一个数可以转换成移位操作,这样能快一点;但是也有网上一些人对这两点提出质疑。
// *
// *
// * link:https://lazydog036.gitee.io/2020/10/29/JAVA%E9%9B%86%E5%90%88%E6%A1%86%E6%9E%B6/#Set%E9%9B%86%E5%90%88%E6%A6%82%E8%BF%B0
// */
//
//
// @Override
// public boolean equals(Object obj) { //重写 equals
// if (this==obj){
// return true;
// }
// if (obj==null){
// return false;
// }if (obj instanceof Person){
// Person person = (Person) obj;
// if (this.name.equals(person.getName())&&this.age==person.getAge()){
// return true;
// }
// }
// return false;
// }
//
//快速生成hashcode和equals
//ALT + Insert
//如下;新版的IDEA生成的内容可能会跟教程的不一样
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return age == person.age && name.equals(person.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
//先按姓名比较,再俺年龄比
@Override
public int compareTo(Person o) {
int n1 = this.getName().compareTo(o.getName());
int n2 = this.age - o.getAge();
return n1==0?n2:n1;
}
}
5.2.3 Comparato接口
创建集合时,并指定比较规则,则person类不需要implements Comparable
package oop5;
import java.util.Comparator;
import java.util.TreeSet;
/**
* TreeSet集合的使用
* Comparator:实现定制比较(比较器)
* Comparable: 可比较的
*/
public class Demo6 {
public static void main(String[] args) {
TreeSet<Person> people= new TreeSet<>(new Comparator<Person>() {
//创建集合,并指定比较规则
@Override
public int compare(Person o1, Person o2) {
int n1 = o1.getAge() - o2.getAge();
int n2 = o1.getName().compareTo(o2.getName());
return n1 == 0?n2:n1;
}
});
Person person1 = new Person("甘雨",3000);
Person person2 = new Person("钟离",6000);
Person person3 = new Person("八重神子",500);
people.add(person1);
people.add(person2);
people.add(person3);
System.out.printf("元素个数%d%n", people.size());
System.out.println(people.toString());
}
}
5.2.4 TreeSet案例
package oop5;
import java.util.Comparator;
import java.util.TreeSet;
/**
* 使用的TreeSet集合实现字符串按照长度进行排序
* Comparator接口实现定制比较
*/
public class Demo7 {
public static void main(String[] args) {
TreeSet<String> treeSet = new TreeSet<>(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
int n1 = o1.length()-o2.length();
int n2 = o1.compareTo(o2);
return n1 == 0 ? n2:n1;
}
});
treeSet.add("芭芭拉");
treeSet.add("琴");
treeSet.add("胡桃");
treeSet.add("巴巴托斯");
treeSet.add("摩拉克斯");
treeSet.add("魈");
treeSet.add("甘雨");
treeSet.add("阿斯托洛吉斯·莫娜·梅姬斯图斯");
treeSet.add("菲谢尔·冯·露弗施洛斯·那菲多特");
treeSet.add("御建鸣神主尊大御所大人");
System.out.println(treeSet.toString());
}
}
六、Map接口与实现类
6.1 Map集合概述
- 用于存储任意键值对(Key-Value)。
- 键:无序、无下标、不允许重复(唯一)。
- 值:无序、无下标、允许重复。
特点:存储一对数据(Key-Value),无序、无下标,键不可重复。
方法:
package oop6;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
* Map接口的使用
* 特点:
* 存储键值对
* 键不能重复,值可以重复
* 无序
*
*/
public class Demo1 {
public static void main(String[] args) {
Map<String,String> map = new HashMap<>();
//添加元素
map.put("CN","中国");
map.put("US","美国");
map.put("UK","英国");
map.put("JP","日本");
map.put("FR","法国");
map.put("RU","俄罗斯");
System.out.println(map.size()); //个数
System.out.println(map.toString());
map.remove("US"); //key键值是第一个,且是唯一的
System.out.println(map.toString());
//遍历
//使用keySet遍历
Set<String> keySet = map.keySet();
for (String key : keySet){
System.out.println(key + map.get(key));
}
//使用entrySet()方法遍历 ,使用entrySet();效率较高
Set<Map.Entry<String, String>> entries = map.entrySet();
for (Map.Entry<String, String> entry :entries){
System.out.println(entry.getKey() + entry.getValue());
}
System.out.println(map.containsKey("CN"));
System.out.println(map.containsValue("泰国"));
}
}
6.2 Map接口
6.3 HashMap使用(重点)
package oop6;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
/**
* HashMap的使用
* 存储结构:
* 哈希表、数组、红黑树
* 使用key可hashcode和equals作为重复判断对象
*/
public class Demo2 {
public static void main(String[] args) {
HashMap<Student , String> students = new HashMap<Student , String>();
Student s1 = new Student("甘雨", 100);
Student s2 = new Student("神里绫华", 101);
Student s3 = new Student("诺诶尔", 102);
students.put(s1,"璃月");
students.put(s2,"稻妻");
students.put(s3,"蒙德");
students.put(new Student("诺诶尔", 102),"蒙德");
System.out.println(students.size());
System.out.println(students.toString());
//删除
// students.remove(s1);
System.out.println(students.toString());
//遍历
//使用keySet
for (Student key : students.keySet()){
System.out.println(key.toString() + students.get(key));
}
//使用entrySet
for (Map.Entry<Student , String> entry:students.entrySet()){
System.out.println(entry.getKey() + entry.getValue());
}
//判断
System.out.println(students.containsKey(s1));
System.out.println(students.containsValue("须弥"));
}
}
package oop6;
import java.util.Objects;
public class Student {
private String name;
private int ID;
public Student(){
}
public Student(String name, int ID) {
this.name = name;
this.ID = ID;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getID() {
return ID;
}
public void setID(int ID) {
this.ID = ID;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", ID=" + ID +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return ID == student.ID && name.equals(student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, ID);
}
}
源码分析总结:
1、HashMap刚创建时,table(哈希桶)为null,节省空间。当添加第一个元素时,容量调整为16
2、当元素个数大于阈值(16*0.75=12)时,会进行扩容,扩容后的大小为原来的两倍,目的是减少调整元素的个数
3、JDK1.8 当每个链表长度大于8时,并且数组长度大于64, 会调整为红黑树,目的提高效率
4、JDK1.8 当链表长度小于6时,调整为链表
5、JDK1.8 以前,链表是头插入,之后是尾部插入
HashSet的底层也是使用的HashMap
6.4Hashtable和Properties
HashTable(了解即可,已经弃用)
JDK1.0就存在,线程安全,运行效率低,不允许null作为key和value
Properties(可在IO框架学习)
HashTable的子类,要求key和value都是String。通常用于配置文件的读取
6.5 TreeMap
实现了SortedMap接口(是Map的子接口),可以对key自动排序。
package oop6;
import java.util.Comparator;
import java.util.Map;
import java.util.TreeMap;
/**
* TreeMap的使用
* 存储结构:红黑树
*/
public class Demo3 {
public static void main(String[] args) {
// TreeMap<Student, String> treeMap = new TreeMap<Student, String>();
//使用比较器Comparator也可以
TreeMap<Student, String> treeMap = new TreeMap<Student, String>(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
int n2 = o1.getID() - o2.getID();
return n2;
}
});
Student s1 = new Student("甘雨", 100);
Student s2 = new Student("神里绫华", 101);
Student s3 = new Student("诺诶尔", 102);
treeMap.put(s1,"璃月");
treeMap.put(s2,"稻妻");
treeMap.put(s3,"蒙德");
// treeMap.put(new Student("诺诶尔", 102),"须弥");
System.out.println(treeMap.toString());
treeMap.remove(s3);
//遍历
//使用keySet
for (Student key : treeMap.keySet()){
System.out.println(key + treeMap.get(key));
}
//使用entrySet
for (Map.Entry<Student,String> entry:treeMap.entrySet()){
System.out.println(entry.getKey()+entry.getValue());
}
//判断
System.out.println(treeMap.containsKey(s1));
System.out.println(treeMap.containsValue("须弥"));
}
}
package oop6;
import java.util.Objects;
public class Student implements Comparable<Student>{
private String name;
private int ID;
public Student(){
}
public Student(String name, int ID) {
this.name = name;
this.ID = ID;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getID() {
return ID;
}
public void setID(int ID) {
this.ID = ID;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", ID=" + ID +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return ID == student.ID && name.equals(student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, ID);
}
@Override
public int compareTo(Student o) {
int n1 = this.name.compareTo(o.getName());
int n2 = this.ID - o.ID;
return n2;
}
}
七、Collections 工具类
集合工具类,定义了除了存取以外的集合常用方法
public static void reverse(List<?> list)//反转集合中元素的顺序public static void shuffle(List<?> list)//随机重置集合元素的顺序public static void sort(List<T> list)//升序排序(元素类型必须实现Comparable接口)
package oop6;
import java.util.*;
/**
* 演示Collections工具类的使用
*
*/
public class Demo4 {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(20);
list.add(15);
list.add(12);
list.add(30);
list.add(6);
System.out.println(list.toString());
//shot排序 升序
Collections.sort(list);
System.out.println(list.toString());
//binarySearch 查找是否含有
int i = Collections.binarySearch(list,13);
System.out.println(i);
//copy 赋值
List<Integer> DEST = new ArrayList<>();
for (int j = 0; j < list.size(); j++) {
DEST.add(0);
}
Collections.copy(DEST,list);
System.out.println(DEST.toString());
//reverse反转
Collections.reverse(list);
System.out.println(list);
//shuffle 打乱
Collections.shuffle(list);
System.out.println(list);
//list 转数组
Integer[] array = list.toArray(new Integer[0]);
System.out.println(array.length);
System.out.println(Arrays.toString(array));
//数组转list
String [] name = { "温迪","钟离","影"};
//集合是一个受限集合,不能添加和删除
List<String> list1 = Arrays.asList(name);
System.out.println(list1);
//基本类型数组转为集合时,需要转成包装类
Integer[] nums = {100,200,300};
List<Integer> list2 = Arrays.asList(nums);
System.out.println(list2);
}
}